
Business Intelligence
Data Center Management
How In-Memory Data Grids Differ from Spark and Storm

Let’s set the story straight. As an in-memory computing vendor, we’ve found that our products often get confused with some popular open-source, in-memory technologies such as Spark and Storm. While each could be placed into the “real-time analytics” category, real-time analytics is much broader than most people may realize.
These innovative technologies are great at what they’re built for, but in-memory data grids (IMDGs) were developed for different purposes. The question comes down to whether you want to use in-memory analytics to provide immediate feedback to operational systems, accelerate analysis of static data sets or process streams of data. First, we’ll provide you with some quick background information on IMDGs. Then we’ll take a look at how IMDGs differ from Spark and Storm.
IMDGs Provide Fast, Scalable Data Storage
IMDGs host data in memory and distribute it across a cluster of commodity servers. Using an object-oriented data storage model, IMDGs provide APIs for reading and updating data objects, typically in under a millisecond, depending on the size of the object. This enables operational systems to use IMDGs for storing, accessing and updating fast-changing “live” data that track the system’s state, all while maintaining quick access times even as the storage workload grows. IMDGs store in-memory data with high availability so that it is continuously available even if a server fails.
IMDGs Perform Data-Parallel Computation
Because IMDGs store data in memory distributed across a cluster of servers, they can easily perform data-parallel computations on stored data; there is no need to migrate data to other servers. 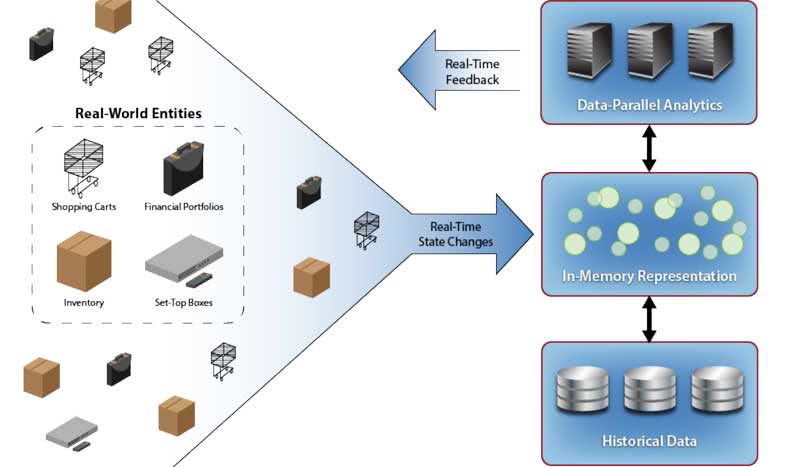 This feature enables IMDGs to provide fast results with minimal overhead, and it makes them well suited to quickly analyze the state of an operational system and provide immediate feedback. The diagram to the right illustrates the use of an IMDG to track the state of real-world entities within an operational system, analyze their behavior in parallel and send feedback to the system.
This feature enables IMDGs to provide fast results with minimal overhead, and it makes them well suited to quickly analyze the state of an operational system and provide immediate feedback. The diagram to the right illustrates the use of an IMDG to track the state of real-world entities within an operational system, analyze their behavior in parallel and send feedback to the system.
What Is Spark?
Developed in the AMPLab at UC Berkeley, Apache Spark is an open source, data-parallel execution engine designed to accelerate Hadoop MapReduce calculations and add related operators by staging data in memory, instead of moving it from disk to memory and back for each operator. By building on top of the Hadoop Distributed File System (HDFS), Spark promises performance up to 100 times faster than Hadoop MapReduce.
A key new mechanism that supports Spark’s programming model is the resilient distributed dataset (RDD) to allow apps to keep working sets in memory for efficient reuse. According to AMPLap, RDDs are, “unchangeable, partitioned collections of objects created through parallel transformations,” and to continue operating properly in the event of failure, “RDDs maintain lineage information that can be used to reconstruct lost partitions.”
How In-Memory Data Grids Are Different from Spark
There are various key differences between using an IMDG to host data-parallel computations and using Spark. IMDGs analyze updatable, highly available, memory-based collections of objects. This makes them well suited for operational environments in which mission-critical data is continuously updated (to track the system’s state), even while analytics computations are ongoing. In contrast, Spark was designed to create, analyze and transform immutable collections of data hosted in memory. 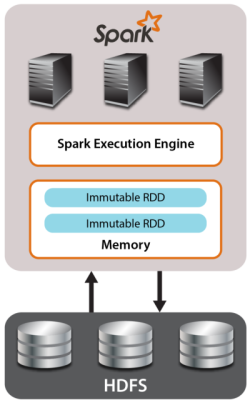 This makes Spark ideal for optimizing the execution of a series of data-parallel operators on static data. The diagram illustrates Spark’s use of memory-hosted RDDs to hold data accessed through its analytics engine.
This makes Spark ideal for optimizing the execution of a series of data-parallel operators on static data. The diagram illustrates Spark’s use of memory-hosted RDDs to hold data accessed through its analytics engine.
Spark is not well suited for operational environments for two reasons. First, individual data items within its RDDs data cannot be updated. In fact, if Spark inputs data from HDFS, changes have to be propagated to HDFS from another data source since HDFS files only can be appended, not updated. Second, RDDs are not highly available. Their fault-tolerance results from reconstructing them from their recorded lineage, which may take substantially more time to complete than server failover by an IMDG. This represents an appropriate tradeoff for Spark because, unlike IMDGs, it focuses on analytics computations of data that do not need to be constantly available. Even though Spark makes different design tradeoffs than IMDGs to support fast analytics, IMDGs can still deliver comparable speedup for Hadoop MapReduce.
How In-Memory Data Grids are Different from Storm
Storm was originally developed by Nathan Marz at BackType to overcome the limitations of batch-oriented Hadoop in continuously analyzing streams of incoming data such as Twitter streams and Web log files. Storm includes two basic entities for processing data streams:
- sprouts, which generate streams of data in the form of ordered tuples, and
- bolts, which process incoming streams and optionally generate outgoing streams for other bolts.
The following diagram illustrates a Storm configuration of streams and bolts processing a set of input streams and generating a set of output streams.
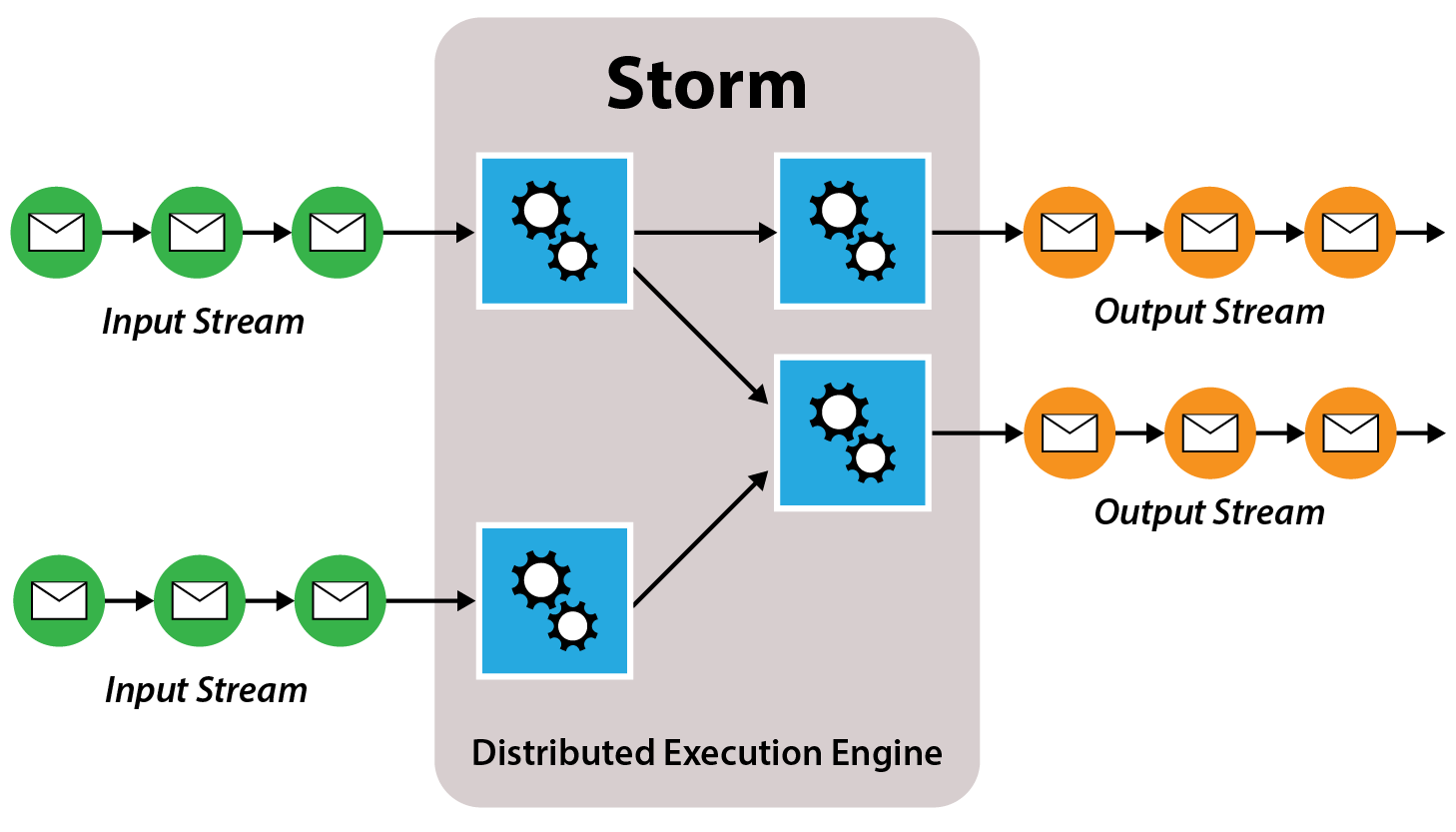
A major strength of Storm is its continuous execution model. Once a configuration has been deployed, incoming data streams can be processed without scheduling delays, thereby providing uninterrupted real-time results. This model overcomes a major drawback of Hadoop MapReduce, which processes data in batch jobs with significant latency (often 15+ seconds) in starting up each job.
IMDGs approximate Storm’s continuous execution model in two ways. First, they allow continuous, overlapped updates to in-memory state, enabling them to handle high arrival rates of incoming data (i.e. thousands of updates per second for each IMDG server in a cluster). Note that both IMDGs and Storm scale out to increase throughput by adding servers to the cluster. Second, some IMDGs, such as ScaleOut hServer, allow data-parallel operations to be performed continuously with very low start-up delay. This allows IMDGs to output a stream of analysis results that matches the low latency required by operational systems.
In a Nutshell: IMDGs, Spark and Storm
IMDGs offer a platform for scalable, memory-based storage and data-parallel computation specifically designed for use in operational systems. Because they incorporate API support for accessing and updating individual data objects and data-parallel analytics, IMDGs are able to easily track the state of operational systems and analyze this state to provide immediate feedback.
Although Spark bears a resemblance to IMDGs with integrated MapReduce, because of its use of memory-based storage and accelerated execution times for parallel computation, it was not designed for use in operational systems and does not provide key features — such as object updating and high availability — needed to make this feasible. Instead, Spark is best suited for very quickly performing a series of analytics on static data or snaphots of incoming data streams.
Storm was designed for a different purpose than IMDGs, namely to analyze streams of data using a continuously running execution pipeline. The more complex, task-oriented computation model fits this purpose well, and as a result, Storm embodies a different set of tradeoffs than IMDGs, such as a focus on stream processing instead of tracking the state of an operational system.
Clearly, the term “real-time analytics” encompasses a variety of solutions designed to meet diverse business requirements. By understanding the differences in these approaches, we can select the most appropriate tool for the job, simplify the design and obtain the best performance.
Ready to find the best BI software solution for your company? Browse product reviews, top blog posts and premium content on our BI resource center page.
[Image courtesy of Wikimedia Commons]

- Vendor


